Курс “Data Science”
Материалы 2021-2022 учебного года
Добро пожаловать в Data Science Club!
Если вы еще не записались на курс, то самое время это сделать:
Гугл-форма для записи на курс DataScience 2022
Для вступления в наш клуб вам надо выполнить несколько заданий.
- Просмотреть следующие видео фрагменты, приведенные ниже
- Установить на свой ноутбук (или стационарный компьютер) R и RStudio в соответствии с теми инструкциям, которые вы найдете в видео.
- Решить задачу, которую вы найдете ниже.
Важно! Почти все, что нам придется делать, изучая язык обработки данных “R”, потребует некоторого владения английским языком. Если у вас он еще не на самом высоком уровне, то не отчаивайтесь. Вот прекрасный переводчик (лучший на настоящее время), который поможет вам понять, что наисано в том или ином тексте, который нужно будет прочитать: DeepL
Видео фрагменты
Установка R и RStudio
Организация рабочего пространства в среде R
Как получить помощь?
Установка пакетов
Вот ссылки, для упрощения поиска сайтов
Собственно язык R https://cran.r-project.org/bin/windows/base/
Среда Rstudio, которая существенно облегчает и ускоряет работу с R. https://www.rstudio.com/products/rstudio/download/
Испытание для вступления в клуб
Найдите как называется первый параметр функции aes() из пакета “ggplot2”.
Ответ надо будет вписать вот в эту гугл-форму
Первые шаги
Уважаемые члены нашего клуба!
Вот видео запись нашего занятия
Задание № 2
Ваша задача - разобраться с тем, как создаются пользовательские функции на языке R. Разобравшись с этим, вам надо будет написать функцию, которая решала бы простейшие уравнения вот такого вида:
\[ a + b \cdot x = c \\ x = \frac{c-a}{b} \]
Эта функция должна работать следующим образом.
# Решение простейшего уравнения с помощью пользовательской функции
eq(a = 1, b = 2, c = 3)## [1] "Решение: x = 1"В качестве решения вам нужно будет заполнить вот эту гугл-форму.
Внимание! Если вы еще не разобрались, как сделать так, чтобы ваша функция выдавала текстовое сообщение “Решение: x =”, то можно пока обойтись просто выводом значения \(x\).
Знакомимся с пакетом “ggplot2”
Для того, чтобы отработать навыки работы с графическим пакетом ggplot2 предлагается посмотреть вот это видео, которое создали Алена Евдокимова и Рената Нематова, когда они еще сами изучали R.
NB! Что-то подобное надо будет сделать и вам, но на другие темы.
Задание 2
Ну а в качестве задания вам надо будет визуализировать данные из вот этого датасета. Это данные, которые демонстрируют результаты анализа связи размера головного мозга человека (Переменная MRINACount, количество пикселей на срезе, полученном на МРТ) и уровня его интеллекта по результатам теста на IQ (Переменная PIQ). Кроме того в базе данных есть еще результаты измерения веса и роста испытуемых.
Вам нужно будет написать код, который в точности воспроизведет вот такую картинку.
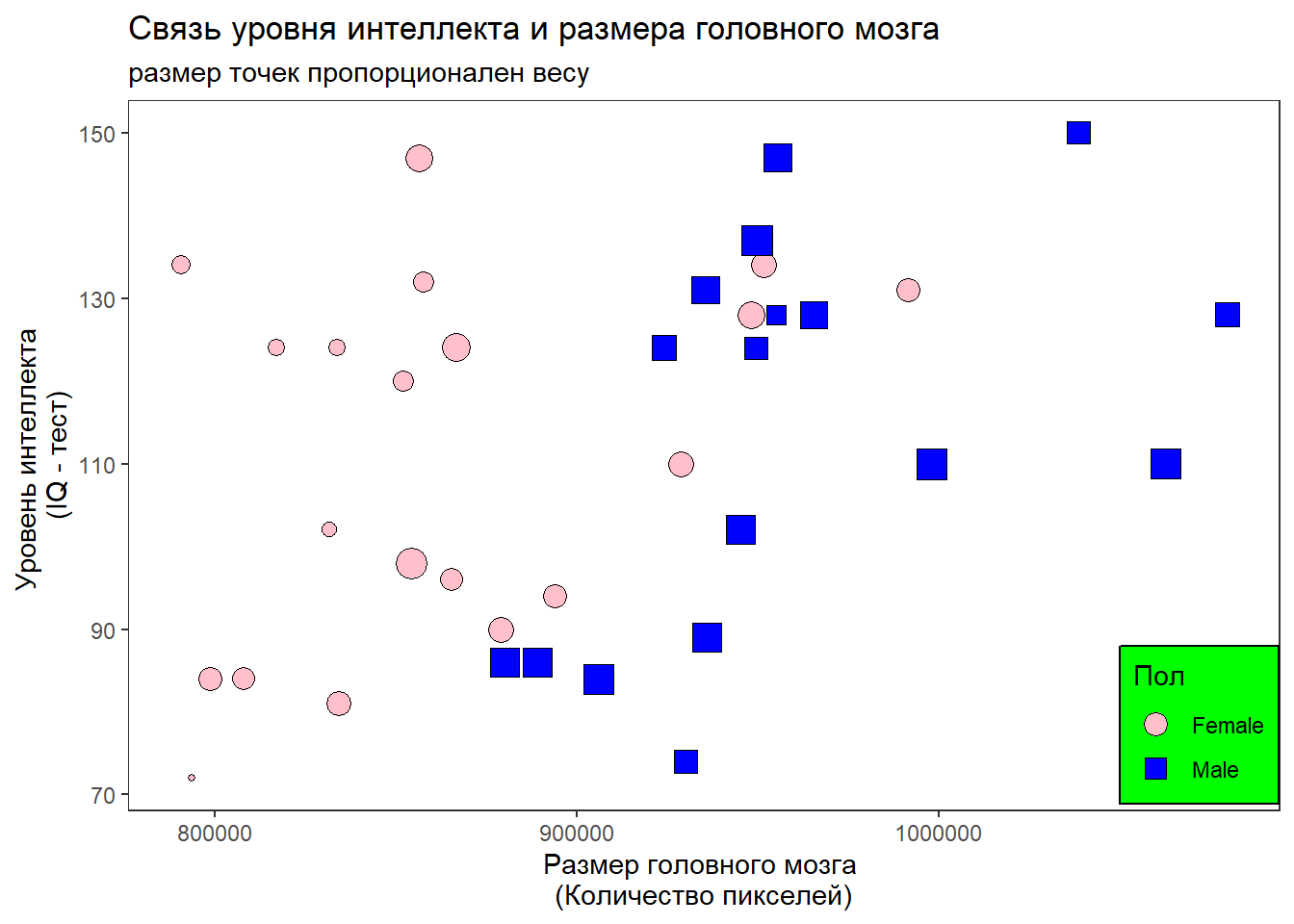
Если у вас какие-то вещи не получились, то присылайте код, который создаст картинку, максимально похожую на ту, что приведена выше.
Ответы кидаем вот в эту гугл-форму
Задание 3
Установите себе пакет vegan. Далее мы будем использовать два датасета из этого пакета: varespec и varechem.
library(vegan)
data(varespec)
head(varespec)[,1:4]## Callvulg Empenigr Rhodtome Vaccmyrt
## 18 0.55 11.13 0.00 0.00
## 15 0.67 0.17 0.00 0.35
## 24 0.10 1.55 0.00 0.00
## 27 0.00 15.13 2.42 5.92
## 23 0.00 12.68 0.00 0.00
## 19 0.00 8.92 0.00 2.42Это данные по обилию растений в сообществах, где пасуться олени в Феноскандии.
data(varechem)
head(varechem)[,1:4]## N P K Ca
## 18 19.8 42.1 139.9 519.4
## 15 13.4 39.1 167.3 356.7
## 24 20.2 67.7 207.1 973.3
## 27 20.6 60.8 233.7 834.0
## 23 23.8 54.5 180.6 777.0
## 19 22.8 40.9 171.4 691.8А это данные по химическим свойствам почвы.
Используя только функции пакета dplyr, преобразуйте эти два датасета в один так, чтобы он выглядел вот таким образом (надо построить только одну цепочку-конвейер, pipe). Новый датасет должен отражать среднее обилие переменной Empenigr (это вороника Empetrum nigrum) на двух типах почв: где калия больше, чем в среднем по всем пробам, и где его меньше, чем в среднем.
## # A tibble: 2 x 2
## K_class Mean_Empenigr
## <chr> <dbl>
## 1 Калия больше среднего 5.78
## 2 Калия меньше среднего 6.99Подсказка Вам понадобится функция case_when().
Ответы кидаем вот в эту гугл-форму
Коллеги!
К сожалению, поездка в Мурманск несколько изменяет планы нашей работы. Поэтому пока работаем саостоятельно.
Задание 4
Друзья!
Пока я в отъезде, давайте начнем учиться так называемому литературному программированию. Вы уже неоднократно от меня слышали про так называемые RMD-файлы, которые создаются с использованием языка Rmarkdown. Вот сейчас этому вы и попытаетесь научиться самостоятельно. Посмотрите видео фрагмент с рассказом о том, что такое Rmarkdown.
NB! Там в конце косяк из-за того, что программа видеозахвата экрана понимает под экраном только то, с чего она начала работать. Увы, это не обойти.
Попробуйте сасостоятельно разобраться в том, как создается RMD-файл. А далее вам нужно будет создать вот такой html-файл.
Удачи!
Надеюсь, в следующий вторник мы сможем все обсудить.
Задание 5
Господа!
Поскольку грядут каникулы, на которые, как выяснилось, многие разъезжаются, то в следующий вторник мы не встречаемся, а работаем самостоятельно. Наша цель - это освоение техники создания RMD-документов с последующим превращением их, для начала, в HTML файлы (потом будем осваивать технику превращения их в WORD, а может руки дойдут и до PDF). В связи с этим вот вам задание.
Для тех, кто хочет все еще раз просмотреть и повторить, - вот запись с прошлой нашей встречи. Видео. “Создание rmd-файлов”. Вот сам rmd-файл, который мы создали на занятии.
В качестве каникулярного задания у вас будет работа по созданию RMD-файла, который будет посвящен одной из глав моей методички по статистическим методам. Я ее давно хотел переделать и можем ее сделать в соавторстве. Для этого надо все перевести в RMD. Там есть и текст и формулы и таблицы и графики.
Тексты можно просто вставлять, копируя их из PDF-файла. Но не забывайте про жирный шрифт, курсив, сноски(!) и заголовки разного уровня.
Только уговор! Все графики (включая те, которые не являются результатом анализа какого-то датафрейма) должны генерироваться чанками с использованием функций пакета ggplot2 (графики нельзя вставлять в виде простого рисунка). Иногда это будет сложно. Но если вы разберетесь и справитесь, то крутость у вас будет неимоверная. Таблицы, давайте тоже договоримся, пусть будут производными от датафреймов (если это возможно). Датафреймы можно набить в экселе и сохранить в формате csv. Далее в чанке должно быть где-то написано чтение этих данных.
Итак, вот сама методичка.
Предлагаю такое разделение по главам
Никита - Глава 1.9
Катя - Глава 2.1
Артур - Глава 2.2 до стр. 28 (до фразы “Теперь перейдем к разговору об анализе размерно-возрастной структуры популяции”.)
Андрей - Глава 2.2 со страницы 28 (с фразы “Теперь перейдем к разговору об анализе размерно-возрастной структуры популяции”.)
Таня - Глава 2.3
Если кто-то еще захочет присоединиться, то пишите.