class: middle, left, inverse, title-slide .title[ # Обобщенные линейные модели с нормальным распределением остатков ] .subtitle[ ## Линейные модели… ] .author[ ### Марина Варфоломеева, Вадим Хайтов, Анастасия Лянгузова, Валентина Домашкина ] .date[ ### Осень 2025 ] --- ## Общая линейная модель --- удобный инструмент описания связей `\(y_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i} + \varepsilon_i\)`, где `\(\varepsilon_i \sim N(0, \sigma)\)`. Предикторы в такой модели могут быть дискретными и непрерывными. <!-- --> --- ## Применимость общих линейных моделей ограничена <br/> `\(y_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i} + \varepsilon_i\)`, где `\(\varepsilon_i \sim N(0, \sigma)\)`. <br/> -- Т.е. на самом деле мы имеем ввиду, что переменная-отклик подчиняется нормальному распределению: `\(y_i \sim N(\mu_i, \sigma)\)` `\(E(y_i) = \mu_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}\)` -- Но если отклик подчиняется другому распределению, такие модели не годятся. <br/> Далее мы будем использовать именно этот способ записи модели (распределение отклика и линейный предиктор) мы будем использовать дальше. --- ## Обобщенные линейные модели Обобщенные линейные модели (Generalized Linear Models, GLM, GLZ, GLIM) позволяют моделировать зависимости не только для нормально-распределенных величин, но и для других распределений. <br/> Не путайте обобщенные линейные модели с общими (General Linear Models, тоже сокращаются как GLM). --- ## Важнейшие распределения из семейства экспоненциальных .pull-left[ Для непрерывных величин - Нормальное распределение - Гамма распределение - Бета распределение (не будем рассматривать) ] .pull-right[ Для дискретных величин - Биномиальное распределение - Распределение Пуассона - Отрицательное биномиальное распределение ] --- ## Нормальное распределение .pull-left[ <!-- --> ] .pull-right[ `$$f(y)= \frac {1}{\sqrt{2 \pi \sigma^2}} \cdot e^{-\frac{1}{2 \sigma^2} (y - \mu)^2}$$` Параметры: - `\(\mu\)` -- среднее; - `\(\sigma\)` -- стандартное отклонение. <br/> Свойства: - `\(E(y) = \mu\)` -- мат. ожидание; - `\(var(y) = \sigma^2\)` -- дисперсия; - `\(-\infty \le y \le +\infty\)`, `\(y \in \mathbb R\)` -- значения. ] ??? Faraway J.J. (2017) Extending the linear model with R, p.154 - написано про variance functions --- ## Гамма-распределение .pull-left[ <!-- --> ] .pull-right[ `\(f(y) = \frac{1}{\Gamma(\nu)}\cdot (\frac{\nu}{\mu})^{\nu} \cdot y^{\nu-1} \cdot e^{\cfrac{y \cdot \nu}{\mu}}\)` Параметры: - `\(\mu\)` -- среднее; - `\(\nu\)` -- определяет степень избыточности дисперсии. <br/> Свойства: - `\(E(y) = \mu\)` -- мат. ожидание; - `\(var(y) = \frac {\mu^2}{\nu}\)` -- дисперсия; - `\(0 < y \le +\infty\)`, `\(y \in \mathbb R\)` -- значения. ] --- ## Биномиальное распределение .pull-left[ <!-- --> ] .pull-right[ `$$f(y) = \frac{n!}{y! \cdot (n-y)!} \cdot \pi^y \cdot (1 - \pi)^{n-y}$$` Параметры: - `\(n\)` -- число объектов в испытании; - `\(\pi\)` -- вероятность успеха в одном испытании. <br/> Свойства: - `\(E(y) = n \cdot \pi\)` -- мат. ожидание; - `\(var(y) = n \cdot \pi \cdot (1-\pi)\)` -- дисперсия; - `\(0 \le y \le +\infty\)`, `\(y \in \mathbb{N}\)` -- значения. ] --- ## Распределение Пуассона .pull-left[ <!-- --> ] .pull-right[ `$$f(y)= \frac{\mu^y \cdot e^{-\mu}}{y!}$$` Параметр: - `\(\mu\)` -- задает среднее и дисперсию. <br/> Свойства: - `\(E(y) = \mu\)` --- мат. ожидание; - `\(var(y) = \mu\)` --- дисперсия; - `\(0 \le y \le +\infty\)`, `\(y \in \mathbb{N}\)` --- значения. ] --- ## Отрицательное биномиальное распределение .pull-left[ <!-- --> ] .pull-right[ `\(f(y) = \frac{\Gamma(y + k)}{\Gamma(k) \cdot \Gamma(y+1)} \cdot (\frac{k}{\mu + k})^k \cdot (1 - \frac{k}{\mu + k})^y\)` Параметры: - `\(\mu\)` -- среднее; - `\(k\)` -- определяет степень избыточности дисперсии. <br/> Свойства: - `\(E(y) = \mu\)` -- мат. ожидание; - `\(var(y) = \mu + \frac {\mu^2}{k}\)` -- дисперсия; - `\(0 \le y \le +\infty\)`, `\(y \in \mathbb{N}\)` -- значения. ] ??? Это смесь Пуассоновского и Гамма распределений: `\(y\)` подчиняется распределению Пуассона с Гамма-распределенным `\(\mu\)`. Приближается к распр. Пуассона при очень больших `\(k\)`. --- ## Обобщенные линейные модели <br/> (Generalized Linear Models) .pull-left[ Обобщенные линейные модели (Nelder, Weddlerburn, 1972) - Позволяют моделировать не только величины, подчиняющиеся нормальному распределению, но и другим распределениям из семейства экспоненциальных. - Подбор коэффициентов делается методом максимального правдоподобия. ] .pull-right[  ] --- ## Отличия обобщенной линейной модели от общей На примере нормального распределения `\(\color{purple}{f(y_i|\theta) = N(\mu_i, \sigma)}\)` -- ### Общая линейная модель состоит из двух компонентов `\(\color{purple}{y_i \sim f(y_i|\theta)}\)` `\(\color{teal}{E(y_i) = \mu_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}}\)` -- ### Обобщенная линейная модель состоит из трех компонентов `\(\color{purple}{y_i \sim f(y_i|\theta)}\)` `\(\color{green}{E(y_i) = \mu_i = g^{-1}(\beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i})}\)` `\(\color{red}{g(\mu_i) = \eta_i}\)` `\(\color{blue}{\eta_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}}\)` - Случайная часть --- `\(\color{purple}{y_i \sim f(y_i|\theta)}\)` --- распределение из семейства экспоненциальных с параметрами `\(\theta\)`. - Фиксированная часть: `\(\color{red}{g()}\)` --- .red[функция связи], трансформирует .green[мат. ожидание отклика] в .blue[линейный предиктор] `\(\color{blue}{\eta_i}\)` (обратная функция связи обозначается `\(\color{green}{g^{-1}()}\)`). --- ## Функция связи .content-box[ `\(\color{purple}{y_i \sim f(y_i|\theta)}\)` `\(\color{green}{E(y_i) = \mu_i = g^{-1}(\beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i})}\)` `\(\color{red}{g(\mu_i) = \eta_i}\)` `\(\color{blue}{\eta_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}}\)` ] <br/> .red[Функция связи] `\(\color{red}{g(\mu)}\)` разная в зависимости .purple[от распределения отклика] `\(\color{purple}{f(y_i|\theta)}\)` --- ## Функция связи: идентичность .content-box[ `\(\color{purple}{y_i \sim f(y_i|\theta)}\)` `\(\color{green}{E(y_i) = \mu_i = g^{-1}(\beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i})}\)` `\(\color{red}{g(\mu_i) = \eta_i}\)` `\(\color{blue}{\eta_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}}\)` ] <br/> .red[Функция связи] `\(\color{red}{g(\mu)}\)` разная в зависимости .purple[от распределения отклика] `\(\color{purple}{f(y_i|\theta)}\)` <br/> `\(\color{purple}{y_i \sim N(\mu_i, \sigma)}\)` `\(\color{green}{E(y_i) = \mu_i \phantom{\frac{e^{\beta_0}}{1 + e^{\beta_0}}}}\)` `\(\color{red}{\mu_i = \eta_i}\)` .red[— идентичность] `\(\color{blue}{\eta_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}}\)` --- ## Функция связи: логарифм .content-box[ `\(\color{purple}{y_i \sim f(y_i|\theta)}\)` `\(\color{green}{E(y_i) = \mu_i = g^{-1}(\beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i})}\)` `\(\color{red}{g(\mu_i) = \eta_i}\)` `\(\color{blue}{\eta_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}}\)` ] <br/> .red[Функция связи] `\(\color{red}{g(\mu)}\)` разная в зависимости .purple[от распределения отклика] `\(\color{purple}{f(y_i|\theta)}\)` <br/> Например, `\(\color{purple}{y_i \sim Poisson(\mu_i)}\)` `\(\color{green}{E(y_i) = e^{\beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}} \phantom{\frac{e^{\beta_0}}{1 + e^{\beta_0}}}}\)` `\(\color{red} {ln(\mu_i) = \eta_i}\)` .red[— логарифм] `\(\color{blue}{\eta_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}}\)` --- ## Функция связи: логит .content-box-grey[ `\(\color{purple}{y_i \sim f(y_i|\theta)}\)` `\(\color{green}{E(y_i) = \mu_i = g^{-1}(\beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i})}\)` `\(\color{red}{g(\mu_i) = \eta_i}\)` `\(\color{blue}{\eta_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}}\)` ] <br/> .red[Функция связи] `\(\color{red}{g(\mu)}\)` разная в зависимости .purple[от распределения отклика] `\(\color{purple}{f(y_i|\theta)}\)` <br/> Например, `\(\color{purple}{y_i \sim Binomial(n = 1, \pi_i)}\)` `\(\color{green}{E(y_i) = \cfrac{e^{\beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}}}{1 + e^{\beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}}}}\)` `\(\color{red} {ln\big(\cfrac{\mu_i}{1 - \mu_i}\big) = \eta_i}\)` .red[— логит] `\(\color{blue}{\eta_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}}\)` --- ## Параметры обобщенных линейных моделей подбирают методом максимального правдоподобия <!-- --> --- ## Параметры обобщенных линейных моделей подбирают методом максимального правдоподобия <!-- --> Для каждого значения предиктора (отложен по оси OX) есть некоторая выборка значений зависимой переменной. --- ## Параметры обобщенных линейных моделей подбирают методом максимального правдоподобия Правдоподобие (likelihood) --- измеряет соответствие реально наблюдаемых данных тем, что можно получить из модели при определенных значениях параметров. .pull-left-45[ <!-- --> ] .pull-right-55[ Это произведение вероятностей данных: `$$L(\theta| y_i) = \Pi^n _{i = 1}\color{purple}{f(y_i| \theta)}$$` ] Параметры модели должны максимизировать значение логарифма правдоподобия (loglikelihood): `$$lnL(\theta| y_i) \longrightarrow \text{max}$$` <br> .small[ Для тех, кому интересно разобраться вот [хорошая визуализация работы ML и тестов, основанных на LR](https://rpsychologist.com/likelihood/) ] .tiny[ Magnusson, K. (2020). Understanding Maximum Likelihood: An interactive visualization (Version 0.1.2) [Web App]. R Psychologist. https://rpsychologist.com/likelihood/ ] --- ## ML-оценки для дисперсий -- смещенные Например, ML оценка обычной выборочной дисперсии будет смещенной: Хотелось бы: `\(\hat\sigma^2 = \cfrac{\sum(y_i - \hat y_i)^2}{n - p - 1}\)`, На самом деле при ML: `\(\hat\sigma^2 = \cfrac{\sum(y_i - \hat y_i)^2}{n}\)`, т.к. в знаменателе не `\(n - p - 1\)`, а `\(n\)`. <br/> Аналогичные проблемы возникают при ML оценках для случайных эффектов в линейных моделях. Это происходит потому, что в смешанной линейной модели `\(\mathbf{Y} = \mathbf{X} \pmb{\beta} + \mathbf{Z} \mathbf{b} + \pmb{\varepsilon}\)` `\(\mathbf{Y} \sim N(\mathbf{X} \pmb{\beta}, \mathbf{V})\)`, где `\(\mathbf{V} = \mathbf{ZDZ'} + \pmb{\Sigma}\)` т.е. одновременно приходится оценивать `\(\pmb{\beta}\)` и `\(\mathbf{V}\)`. --- class: middle, center, inverse # Пример -- энергетическая ценность икры --- ## Пример -- энергетическая ценность икры Один из показателей, связанных с жизнеспособностью икры -- доля сухого вещества. Она пропорциональна количеству запасенной энергии. .pull-left[ Отличается ли энергетическая ценность икры большой озерной форели в сентябре и ноябре? ] .pull-right[  ] .small[ Данные: Lantry et al., 2008 Источник: пакет Stat2Data ] --- ## Открываем данные ```r library(Stat2Data) data(FishEggs) ``` Все ли правильно открылось? ```r str(FishEggs) ``` ``` 'data.frame': 35 obs. of 4 variables: $ Age : int 7 8 8 9 9 9 9 10 10 11 ... $ PctDM: num 37.4 38 37.5 39 37.9 ... $ Month: Factor w/ 2 levels "Nov","Sep": 1 1 1 1 1 1 1 1 1 1 ... $ Sept : int 0 0 0 0 0 0 0 0 0 0 ... ``` Нет ли пропущенных значений? ```r colSums(is.na(FishEggs)) ``` ``` Age PctDM Month Sept 0 0 0 0 ``` --- ## Меняем порядок уровней факторов Уровни факторов в исходных данных: ```r levels(FishEggs$Month) ``` ``` [1] "Nov" "Sep" ``` Делаем базовым уровнем сентябрь. ```r FishEggs$Month <- relevel(FishEggs$Month, ref = 'Sep') ``` Теперь уровни в хронологическом порядке: ```r levels(FishEggs$Month) ``` ``` [1] "Sep" "Nov" ``` --- ## Объемы выборок ```r table(FishEggs$Month) ``` ``` Sep Nov 14 21 ``` --- ## Ищем выбросы ```r library(ggplot2) theme_set(theme_bw()) ``` ```r library(cowplot) gg_dot <- ggplot(FishEggs, aes(y = 1:nrow(FishEggs))) + geom_point() plot_grid(gg_dot + aes(x = Age), gg_dot + aes(x = PctDM), nrow = 1) ``` <!-- --> --- ## Модель для описания питательной ценности икры ### GLM с нормальным распределением отклика `\(y_i \sim N(\mu_i, \sigma)\)` `\(E(y_i) = \mu_i\)` `\(\mu_i = \eta_i\)` --- функция связи "идентичность" (identity) `\(\eta_i = \beta_0 + \beta_1 x_{1i} + ... + \beta_{p-1}x_{p-1\,i}\)` -- ### Модель зависимости в примере Как зависит питательная ценность икры от месяца вылова рыбы (сентябрь или ноябрь) с учетом ковариаты (возраста рыбы) и их взаимодействия. `\(PctDM_i \sim N(\mu_i, \sigma)\)` `\(E(PctDM_i) = \mu_i\)` `\(\mu_i = \eta_i\)` `\(\eta_i = \beta_0 + \beta_1 Age_{i} + \beta_2 Month_{Nov\,i} + \beta_{3} Age_{i} Month_{Nov\,i}\)` - `\(PctDM_i\)` --- содержание сухого вещества в икре; - `\(Age_{i}\)` --- возраст рыбы; - `\(Month_{Nov\,i}\)` -- переменная-индикатор для уровня `\(Month_{Nov\,i} = 1\)`. ??? В генеральной совокупности параметры модели `\(\beta_0, ..., \beta_3\)`. Подобрав модель, мы получим их оценки `\(b_0, ..., b_3\)`. --- ## Подбираем модель ```r mod <- glm(PctDM ~ Age * Month, data = FishEggs) mod ``` ``` Call: glm(formula = PctDM ~ Age * Month, data = FishEggs) Coefficients: (Intercept) Age MonthNov Age:MonthNov 38.1211 -0.2396 1.2762 0.0214 Degrees of Freedom: 34 Total (i.e. Null); 31 Residual Null Deviance: 84 Residual Deviance: 47.8 AIC: 120 ``` -- ```r # Чтобы записать модель, нужна еще сигма. sigma(mod) ``` ``` [1] 1.242 ``` -- `\(PctDM_i \sim N(\mu_i, 1.24)\)` `\(E(PctDM_i) = \mu_i\)` `\(\mu_i = \eta_i\)` `\(\eta_i = 38.12 - 0.24 Age_{i} + 1.28 Month_{Nov\,i} + 0.02 Age_{i} Month_{Nov\,i}\)` --- class: middle, center, inverse # Диагностика модели --- ## Разновидности остатков в GLM .pull-left[ ### Остатки в масштабе отклика <br/>(response residuals) `$$e_i = y_i - E(y_i)$$` <br/> - Это разница между наблюдаемым и предсказанным значениями. - Аналог (и синоним) "сырых" остатков в простой линейной регрессии. ] -- .pull-right[ ### Пирсоновские остатки <br/>(Pearson's residuals) `$$r_{p\,i} = \frac{y_i - E(y_i)}{\sqrt{var(y_i)}}$$` - Это обычные остатки, деленные на стандартную ошибку предсказанного значения. - Аналог стандартизованных остатков в простой линейной регрессии. ] -- .pull-left[ ```r resid(mod, type = 'response')[1:5] ``` ``` 1 2 3 4 5 -0.5198 0.3984 -0.2016 1.5166 0.4666 ``` ] .pull-right[ ```r resid(mod, type = 'pearson')[1:5] ``` ``` 1 2 3 4 5 -0.5198 0.3984 -0.2016 1.5166 0.4666 ``` ] Для GLM с нормальным распределением отклика оба типа остатков одинаковы. --- ## Условия применимости GLM с нормальным распределением отклика -- - Случайность и независимость наблюдений внутри групп. - Нормальное распределение остатков. - Гомогенность дисперсий остатков. - Отсутствие коллинеарности предикторов. --- ## Проверка на коллинеарность Мы и так знаем, что в параметризации индикаторных переменных взаимодействие будет коллинеарно со своими составляющими (и это нормально, см. прошлую лекцию). Важно проверить, будут ли коллинеарны другие предикторы. ```r library(car) vif(update(mod, . ~ . - Age:Month)) ``` ``` Age Month 1.007 1.007 ``` -- Коллинеарности нет. --- ## Данные для анализа остатков ```r mod_diag <- fortify(mod) # функция из пакета ggplot2 head(mod_diag) ``` ``` PctDM Age Month .hat .sigma .cooksd .fitted .resid .stdresid 1 37.35 7 Nov 0.15819 1.258 0.0097750 37.87 -0.5198 -0.4561 2 38.05 8 Nov 0.11550 1.260 0.0037963 37.65 0.3984 0.3410 3 37.45 8 Nov 0.11550 1.262 0.0009725 37.65 -0.2016 -0.1726 4 38.95 9 Nov 0.08317 1.229 0.0368744 37.43 1.5166 1.2751 5 37.90 9 Nov 0.08317 1.260 0.0034902 37.43 0.4666 0.3923 6 36.45 9 Nov 0.08317 1.249 0.0155048 37.43 -0.9834 -0.8269 ``` --- ## График расстояния Кука ```r ggplot(mod_diag, aes(x = 1:nrow(mod_diag), y = .cooksd)) + geom_bar(stat = 'identity') + geom_hline(yintercept = 1, linetype = 2) ``` <!-- --> Влиятельных наблюдений нет. --- ## График остатков от предсказанных значений ```r gg_resid <- ggplot(data = mod_diag, aes(x = .fitted, y = .stdresid)) + geom_point() + geom_hline(yintercept = 0) gg_resid ``` 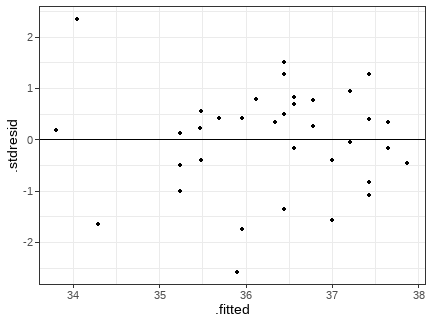<!-- --> -- Влиятельных наблюдений нет. Мало данных в области с небольшими предсказанными значениями. --- ## График зависимости остатков от предикторов в модели ```r ggplot(data = mod_diag, aes(x = Age, y = .stdresid)) + geom_point() + geom_hline(yintercept = 0) ggplot(data = mod_diag, aes(x = Month, y = .stdresid)) + geom_boxplot() + geom_hline(yintercept = 0) ``` <!-- --> -- Нет выраженной гетероскедастичности. --- class: middle, center, inverse # Тестирование значимости коэффициентов --- ## Тест Вальда для коэффициентов GLM `\(H_0: \beta_k = 0\)` `\(H_A: \beta_k \ne 0\)` `$$\frac{b_k - \beta_k} {SE_{b_k}} = \frac{b_k} {SE_{b_k}} \sim N(0, 1)$$` - `\(b_k\)` --- оценка коэффициента GLM. <br/> -- Хорошо работает только на больших выборках (Agresty, 2007). Если приходится оценивать `\(\sigma\)`, то `\(\frac{b_k} {SE_{b_k}} \sim t_{(df = n - p)}\)` - `\(n\)` --- объем выборки. - `\(p\)` --- число параметров модели. ??? Wasserman, 2006. All of Statistics. Краткий рассказ о тесте Вальда. Agresty 2007/ An introduction to categorical data analysis. Предостережение о том, что тест Вальда плохо себя ведет на малых выборках. https://en.wikipedia.org/wiki/Abraham_Wald Абрахам Вальд, венгерский математик, в 1938 г эмигрировал в США, во время войны изучал как распределены повреждения самолетов, в 1950м погиб в авиакатастрофе в Индии. --- ## В `summary()` записаны результаты теста Вальда С увеличением возраста рыбы на год процент сухого вещества в икре снижается на 0.24% (тест Вальда, `\(t_{df = 31} = -2.62\)`, p = 0.013). Это происходит одинаково в сентябре и ноябре. Энергетическая ценность икры в сентябре и ноябре не различается. .small[ ```r summary(mod) ``` ``` Call: glm(formula = PctDM ~ Age * Month, data = FishEggs) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 38.1211 1.0644 35.82 <2e-16 *** Age -0.2396 0.0913 -2.62 0.013 * MonthNov 1.2762 1.5119 0.84 0.405 Age:MonthNov 0.0214 0.1278 0.17 0.868 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for gaussian family taken to be 1.543) Null deviance: 83.962 on 34 degrees of freedom Residual deviance: 47.829 on 31 degrees of freedom AIC: 120.3 Number of Fisher Scoring iterations: 2 ``` ] --- class: middle, center, inverse # Анализ девиансы --- ## Шкала для сравнения моделей -- **Насыщенная модель** --- каждое уникальное наблюдение (сочетание значений предикторов) описывается одним из `\(n\)` параметров. `\(lnL_{saturated} = 0\)` `\(df_{saturated} = n - p_{saturated} = n - n = 0\)` -- **Предложенная модель** --- модель, подобранная в данном анализе `\(\hat y_i = \beta_0 + \beta_1x_{1i} + \ldots + \beta_{p - 1} x_{p - 1\,i}\)`. `\(lnL_{model} \ne 0\)` `\(df_{model} = n - p_{model}\)` -- **Нулевая модель** -- все наблюдения описываются одним параметром (средним) `\(\hat y_i = \beta_0\)`. `\(lnL_{null} \ne 0\)` `\(df_{null} = n - p_{null} = n - 1\)` --- ## Девианса Это мера различия правдоподобий двух моделей (оценка разницы логарифмов правдоподобий). **Остаточная девианса** `\(d_{residual} = 2(lnL_{saturated} - lnL_{model}) = -2 lnL_{model}\)` **Нулевая девианса** `\(d_{null} = 2(lnL_{saturated} - lnL_{null}) = -2 lnL_{null}\)` <br/> Сравнение нулевой и остаточной девианс позволяет судить о статистической значимости модели в целом (при помощи теста отношения правдоподобий). `\(d_{null} - d_{residual} = - 2(lnL_{null} - lnL_{model}) = 2(lnL_{model} - lnL_{null})\)` ??? Остаточная девианса показывает, насколько предложенная модель хуже насыщенной. Нулевая девианса показывает насколько нулевая отличается от насыщенной - т.е. полный диапазон изменения логарифма правдоподобия. Сравнение нулевой и остаточной девианс девианс показывает, насколько предложенная модель лучше нулевой. --- ## Тест отношения правдоподобий (Likelihood Ratio Test) Тест отношения правдоподобий (Wilks, 1938) используется для сравнения правдоподобий `$$LRT = 2ln\Big(\frac{L_{M_1}}{L_{M_2}}\Big) = 2(lnL_{M_1} - lnL_{M_2})$$` - `\(M_1\)` и `\(M_2\)` --- вложенные модели ( `\(M_1\)` --- более полная, `\(M_2\)` --- уменьшенная), - `\(L_{M_1}\)`, `\(L_{M_2}\)` --- правдоподобия, - `\(lnL_{M_1}\)`, `\(lnL_{M_2}\)` --- логарифмы правдоподобий. Сравниваются __вложенные модели, подобранные методом максимального правдоподобия__. Разница логарифмов правдоподобий `\(LRT\)` имеет распределение, которое можно аппроксимировать распределением `\(\chi^2\)` с числом степеней свободы `\(df = df_{M_2} - df_{M_1}\)`. ??? (Wilks, 1938) --- ## LRT используется для сравнения моделей Для тестирования значимости модели целиком: `$$LRT = 2ln\Big(\frac{L_{model}}{L_{null}}\Big) = 2(lnL_{model} - lnL_{null}) = d_{null} - d_{residual}$$` `\(df = df_{null} - df_{model} = (n - 1) - (n - p_{model}) = p_{model} - 1\)` <br/> Для тестирования значимости предикторов: `$$LRT = 2ln\Big(\frac{L_{model}}{L_{reduced}}\Big) = 2(lnL_{model} - lnL_{reduced})$$` `\(df = df_{reduced} - df_{model} = (n - p_{reduced}) - (n - p_{model}) = p_{model} - p_{reduced}\)` ??? Остаточная девианса показывает, насколько предложенная модель хуже насыщенной. Нулевая девианса показывает насколько нулевая отличается от насыщенной - т.е. полный диапазон изменения логарифма правдоподобия. Сравнение нулевой и остаточной девианс девианс показывает, насколько предложенная модель лучше нулевой. --- ## Тестируем значимость модели целиком при помощи LRT ```r ?anova.glm ``` ```r null_model <- glm(PctDM ~ 1, data = FishEggs) anova(null_model, mod, test = 'Chi') ``` ``` Analysis of Deviance Table Model 1: PctDM ~ 1 Model 2: PctDM ~ Age * Month Resid. Df Resid. Dev Df Deviance Pr(>Chi) 1 34 84.0 2 31 47.8 3 36.1 0.000033 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ``` --- ## Тестируем значимость предикторов при помощи LRT Используем II тип тестов ("II тип сумм квадратов"): **1. Тестируем значимость взаимодействия** ```r drop1(mod, test = 'Chi') ``` ``` Single term deletions Model: PctDM ~ Age * Month Df Deviance AIC scaled dev. Pr(>Chi) <none> 47.8 120 Age:Month 1 47.9 118 0.0317 0.86 ``` --- ## 2. Тестируем значимость предикторов, когда взаимодействие удалено ```r mod_no_int <- update(mod, . ~ . -Age:Month) drop1(mod_no_int, test = 'Chi') ``` ``` Single term deletions Model: PctDM ~ Age + Month Df Deviance AIC scaled dev. Pr(>Chi) <none> 47.9 118 Age 1 67.6 128 12.1 0.00051 *** Month 1 67.1 128 11.8 0.00058 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ``` --- ## Запись результатов LRT-тестов значимости предикторов Содержание сухого вещества в икре зависит от возраста рыбы и месяца (p < 0.01, тест отношения правдоподобий, табл. 1). Характер зависимости энергетической ценности икры от возраста одинаков в сентябре и ноябре. <table> <caption>Анализ девиансы для модели зависимости энергетической ценности икры от возраста рыбы, месяца и их взаимодействия. Тесты II типа. df --- число степеней свободы, D --- девианса, p --- уровень значимости.</caption> <thead> <tr> <th style="text-align:left;"> Предиктор </th> <th style="text-align:right;"> df </th> <th style="text-align:right;"> D </th> <th style="text-align:left;"> p </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> - </td> <td style="text-align:right;"> </td> <td style="text-align:right;"> 47.83 </td> <td style="text-align:left;"> </td> </tr> <tr> <td style="text-align:left;"> Возраст:Месяц </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 47.87 </td> <td style="text-align:left;"> 0.86 </td> </tr> <tr> <td style="text-align:left;"> Возраст </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 67.64 </td> <td style="text-align:left;"> <0.01 </td> </tr> <tr> <td style="text-align:left;"> Месяц </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 67.13 </td> <td style="text-align:left;"> <0.01 </td> </tr> </tbody> </table> --- class: middle, center, inverse # Описание качества подгонки GLM --- ## Доля объясненной девиансы **Остаточная девианса** `\(d_{residual} = 2(lnL_{saturated} - lnL_{model}) = -2 lnL_{model}\)` **Нулевая девианса** `\(d_{null} = 2(lnL_{saturated} - lnL_{null}) = -2 lnL_{null}\)` <br/> **Доля объясненной девиансы** `\(\cfrac{d_{null} - d_{residual}}{d_{null}}\)` <br/> -- Доля объясненной девиансы — аналог `\(R^2\)`, одна из характеристик качества подгонки модели. -- Долю объясненной девиансы легко вычислить ```r (mod$null.deviance - mod$deviance) / mod$null.deviance ``` ``` [1] 0.4303 ``` Модель объясняет 43% девиансы. --- class: middle, center, inverse # График предсказаний модели --- ## Задание 1 Постройте график предсказаний модели. --- ## Данные для графика предсказаний ```r library(dplyr) New_Data <- FishEggs %>% group_by(Month) %>% do(data.frame(Age = seq(min(.$Age), max(.$Age), length.out = 100))) head(New_Data) ``` ``` # A tibble: 6 × 2 # Groups: Month [1] Month Age <fct> <dbl> 1 Sep 7 2 Sep 7.11 3 Sep 7.22 4 Sep 7.33 5 Sep 7.44 6 Sep 7.56 ``` --- ## Предсказания при помощи `predict()` ```r Predictions <- predict(mod, newdata = New_Data, se.fit = TRUE) New_Data$fit <- Predictions$fit # Предсказанные значения New_Data$se <- Predictions$se.fit # Стандартные ошибки t_crit <- qt(0.975, df = nrow(FishEggs) - length(coef(mod)) - 1) # t для дов. инт. New_Data$lwr <- New_Data$fit - t_crit * New_Data$se New_Data$upr <- New_Data$fit + t_crit * New_Data$se head(New_Data) ``` ``` # A tibble: 6 × 6 # Groups: Month [1] Month Age fit se lwr upr <fct> <dbl> <dbl> <dbl> <dbl> <dbl> 1 Sep 7 36.4 0.499 35.4 37.5 2 Sep 7.11 36.4 0.491 35.4 37.4 3 Sep 7.22 36.4 0.484 35.4 37.4 4 Sep 7.33 36.4 0.476 35.4 37.3 5 Sep 7.44 36.3 0.469 35.4 37.3 6 Sep 7.56 36.3 0.462 35.4 37.3 ``` --- ## Данные для графика вручную ```r X <- model.matrix(~ Age * Month, data = New_Data) # Модельная матрица betas <- coef(mod) # Коэффициенты New_Data$fit <- X %*% betas # Предсказанные значения New_Data$se <- sqrt(diag(X %*% vcov(mod) %*% t(X))) # Стандартные ошибки t_crit <- qt(0.975, df = nrow(FishEggs) - length(coef(mod)) - 1) # t для дов. инт. New_Data$lwr <- New_Data$fit - t_crit * New_Data$se New_Data$upr <- New_Data$fit + t_crit * New_Data$se head(New_Data) ``` ``` # A tibble: 6 × 6 # Groups: Month [1] Month Age fit[,1] se lwr[,1] upr[,1] <fct> <dbl> <dbl> <dbl> <dbl> <dbl> 1 Sep 7 36.4 0.499 35.4 37.5 2 Sep 7.11 36.4 0.491 35.4 37.4 3 Sep 7.22 36.4 0.484 35.4 37.4 4 Sep 7.33 36.4 0.476 35.4 37.3 5 Sep 7.44 36.3 0.469 35.4 37.3 6 Sep 7.56 36.3 0.462 35.4 37.3 ``` --- ## График предсказаний модели ```r Plot_egg <- ggplot(New_Data, aes(x = Age, y = fit)) + geom_ribbon(alpha = 0.2, aes(ymin = lwr, ymax = upr, group = Month)) + geom_line(aes(colour = Month), size = 1) + geom_point(data = FishEggs, aes(x = Age, y = PctDM, colour = Month)) Plot_egg ``` <!-- --> --- class: middle, center, inverse # Отбор моделей для GLM (model selection) --- ## Подбор "оптимальной" модели В подобранной модели можно протестировать значимость влияния предикторов и их взаимодействия и на этом остановиться. Или можно упростить модель, аналогично тому, как мы это делали со множественной линейной регрессией, но использовав LRT вместо F-теста. --- ## Пытаемся сократить модель ```r mod_no_int <- update(mod, . ~ . -Age:Month) drop1(mod_no_int, test = 'Chi') ``` ``` Single term deletions Model: PctDM ~ Age + Month Df Deviance AIC scaled dev. Pr(>Chi) <none> 47.9 118 Age 1 67.6 128 12.1 0.00051 *** Month 1 67.1 128 11.8 0.00058 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ``` Если мы решили "сократить" модель, то теперь придется описать модель `mod_no_int`. --- ## Уравнение сокращенной модели Как зависит питательная ценность икры от месяца вылова рыбы (сентябрь или ноябрь) с учетом ковариаты (возраста рыбы) и их взаимодействия. ```r mod_no_int ``` ``` Call: glm(formula = PctDM ~ Age + Month, data = FishEggs) Coefficients: (Intercept) Age MonthNov 38.000 -0.229 1.519 Degrees of Freedom: 34 Total (i.e. Null); 32 Residual Null Deviance: 84 Residual Deviance: 47.9 AIC: 118 ``` .pull-left[ ```r #Чтобы записать модель,нужна сигма sigma(mod_no_int) ``` ``` [1] 1.223 ``` ] -- .pull-right[ `\(PctDM_i \sim N(\mu_i, 1.22)\)` `\(E(PctDM_i) = \mu_i\)` `\(\mu_i = \eta_i\)` `\(\eta_i = 38.0 - 0.23 Age_{i} + 1.52 Month_{Nov\,i}\)` - `\(PctDM_i\)` --- содержание сухого вещества в икре; - `\(Age_{i}\)` --- возраст рыбы. ] --- class: middle, center, inverse # Информационные критерии --- еще один способ сравнения или упрощения моделей --- ## Информационный критерий Акаике (Akaike Information Criterion, AIC) .pull-left-66[ `$$AIC = -2 logLik + 2p$$` - `\(logLik\)` --- логарифм правдоподобия для модели; - `\(2p\)` --- штраф за введение в модель `\(p\)` параметров, т.е. за "сложность" модели/ AIC --- это мера потери информации, которая происходит, если реальность описывать этой моделью (Akaike 1974) AIC --- относительная мера качества модели. Т.е. не бывает какого-то "хорошего" AIC. Значения AIC можно интерпретировать только в сравнении с AIC для других моделей: чем меньше AIC --- тем лучше модель. <br/> __Важно!__ Информационные критерии можно использовать для сравнения __даже для невложенных моделей__. Но модели должны быть __подобраны с помощью ML__ и __на одинаковых данных__! ] .pull-right-33[  ] --- ## Некоторые другие информационные критерии |Критерий | Название | Формула| |------ | ------ | ------| |AIC | Информационный критерий Акаике | `\(AIC = -2 logLik + 2p\)`| |BIC | Байесовский информационный критерий | `\(BIC = -2 logLik + p \cdot ln(n)\)`| |AICc | Информационный критерий Акаике с коррекцией для малых выборок (малых относительно числа параметров: `\(n/p < 40\)`, Burnham, Anderson, 2004) | `\(AIC_c = -2 logLik + 2p + \frac{2p(p + 1)}{n - p - 1}\)`| - `\(logLik\)` --- логарифм правдоподобия для модели; - `\(p\)` --- число параметров; - `\(n\)` --- число наблюдений. --- ## Как рассчитать AIC в GLM? `$$AIC = -2 logLik + 2p$$` __В GLM с нормальным распределением отклика число параметров --- это число коэффициентов + 1__, т.к. появился дополнительный параметр `\(\sigma\)` `\(PctDM_i \sim N(\mu_i, 1.22)\)` `\(E(PctDM_i) = \mu_i\)` `\(\mu_i = \eta_i\)` `\(\eta_i = 38.0 - 0.23 Age_{i} + 1.52 Month_{Nov\,i}\)` ```r (p <- length(coef(mod_no_int)) + 1) # число параметров ``` ``` [1] 4 ``` ```r logLik(mod_no_int) # Логарифм правдоподобия ``` ``` 'log Lik.' -55.14 (df=4) ``` ```r as.numeric(-2 * logLik(mod_no_int) + 2 * p) ``` ``` [1] 118.3 ``` ```r AIC(mod_no_int) # Есть готовая функция ``` ``` [1] 118.3 ``` --- ## AIC удобно использовать для сравнения моделей, даже невложенных Пусть у нас есть несколько моделей: ```r mod <- glm(formula = PctDM ~ Age * Month, data = FishEggs) mod_no_int <- glm(formula = PctDM ~ Age + Month, data = FishEggs) mod_age <- glm(formula = PctDM ~ Age, data = FishEggs) mod_month <- glm(formula = PctDM ~ Month, data = FishEggs) ``` ```r AIC(mod, mod_no_int, mod_age, mod_month) ``` ``` df AIC mod 5 120.3 mod_no_int 4 118.3 mod_age 3 128.1 mod_month 3 128.4 ``` Судя по AIC, лучшая модель `mod_no_int`. Если значения AIC различаются всего на 1-2 единицу --- такими различиями можно пренебречь и выбрать более простую модель (`mod_no_int`). --- ## Take-home messages - Обобщенные линейные модели (Generalized Linear Models, GLM) позволяют моделировать зависимости для откликов с распределением из семейства экспоненциальных <br/> -- - Для тестирования предикторов в GLM используются: - Тесты Вальда для коэффициентов (плохо на малых выборках). - Тесты отношения правдоподобий вложенных моделей (более точно). - Доля объясненной девиансы оценивает качество подгонки GLM <br/> -- - Сравнивая модели можно отбраковать переменные, включение которых в модель не улучшает ее - __Метод сравнения моделей нужно выбрать заранее, еще до анализа__ --- ## Что почитать + .red[Zuur, A.F. and Ieno, E.N., 2016. A protocol for conducting and presenting results of regression-type analyses. Methods in Ecology and Evolution, 7(6), pp.636-645.] + Кабаков Р.И. R в действии. Анализ и визуализация данных на языке R. М.: ДМК Пресс, 2014 + .red[Zuur, A., Ieno, E.N. and Smith, G.M., 2007. Analyzing ecological data. Springer Science & Business Media.] + Quinn G.P., Keough M.J. 2002. Experimental design and data analysis for biologists + Logan M. 2010. Biostatistical Design and Analysis Using R. A Practical Guide